
Data engineering teams play a crucial role in modern day facts driven businesses. Businesses generate massive amounts of data each day, and this information needs to be gathered, processed, saved, and organized for evaluation. Data engineering teams are liable for constructing and preserving the infrastructure that allows agencies to transform uncooked facts into valuable insights.
A properly-dependent information engineering group guarantees that statistics flows smoothly across systems, allowing analysts, facts scientists, and enterprise leaders to make informed selections. Without a reliable statistics infrastructure, agencies battle to make use of their facts successfully.
Role of Data Engineering in Modern Businesses
Data engineering has grow to be one of the maximum important additives of digital transformation. Companies depend on correct and well timed facts to optimize operations, recognize customer behavior, and enhance choice-making.
Data engineering teams layout structures that acquire information from diverse resources which include programs, databases, APIs, and IoT devices. They then transform and store this facts in centralized structures like information warehouses or statistics lakes.
These groups make sure that facts is to be had, easy, and dependent for enterprise intelligence equipment and gadget getting to know models. As organizations hold to invest in facts analytics, the significance of records engineering teams keeps to grow.
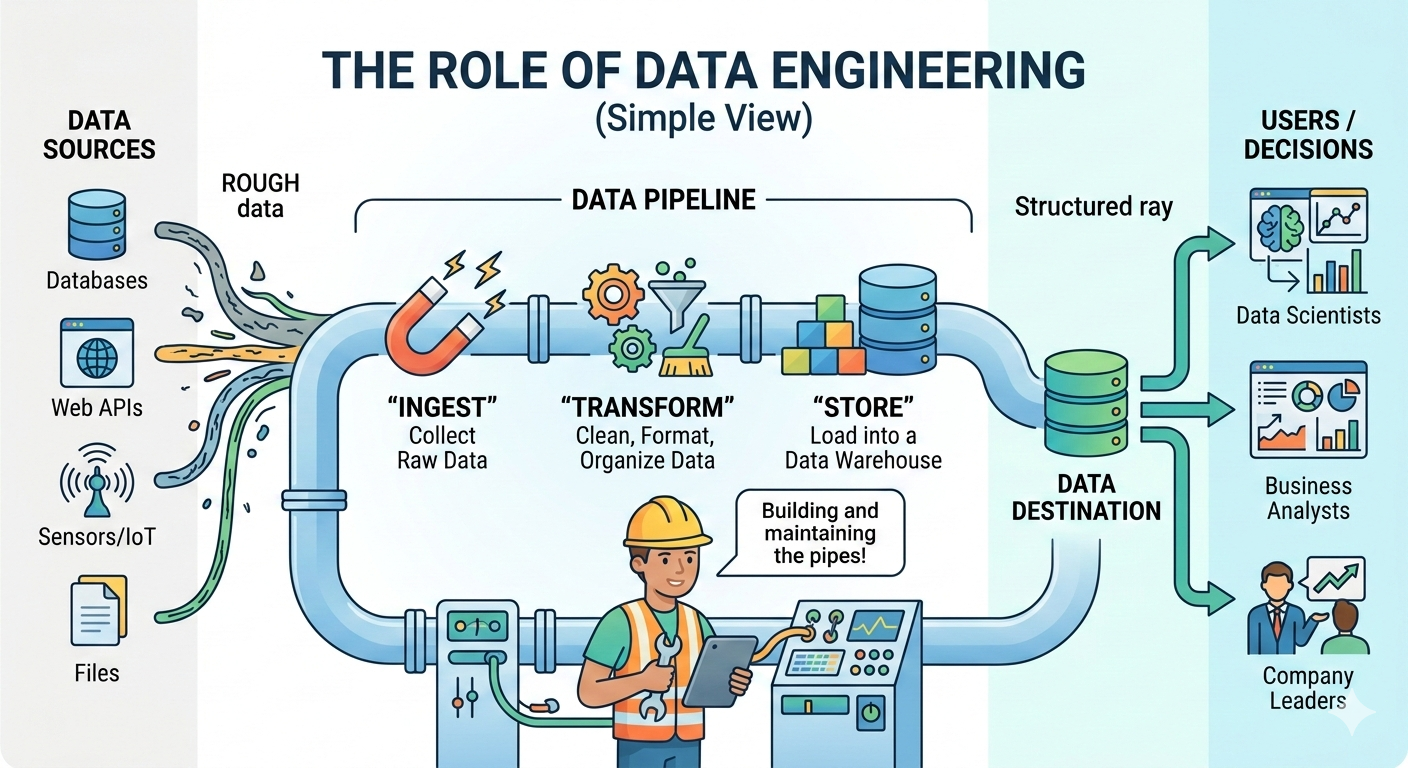
Key Responsibilities of Data Engineering Teams
Data engineering teams take care of several technical duties that help the overall records atmosphere of an corporation.
One in their fundamental responsibilities is constructing data pipelines. Data pipelines automate the method of collecting and shifting records between structures. These pipelines allow corporations to get right of entry to real-time or near-actual-time statistics for analytics.
Another critical obligation is handling records garage systems. Engineers design and keep platforms inclusive of statistics warehouses and facts lakes that save big volumes of established and unstructured statistics.
Data engineering groups additionally attention on optimizing performance and scalability. As records volume will increase, infrastructure must be able to cope with growing workloads without overall performance troubles.
Essential Skills for Data Engineers
A a hit statistics engineering team requires specialists with a strong combination of technical and analytical abilities.
Programming is one of the most essential skills for records engineers. Languages which includes Python, Java, and Scala are extensively used for building statistics pipelines and processing massive datasets.
- Data Modeling
- ETL Pipeline Development
- SQL and Database Management
- Cloud Computing (AWS, Azure, GCP)
- Big Data Technologies (Spark, Hadoop)
Database management is another key talent. Data engineers ought to recognize SQL and NoSQL databases to control and prepare records efficiently.
Cloud computing know-how is also essential. Many corporations use cloud platforms to save and system huge datasets. Engineers have to be familiar with cloud services that assist data infrastructure.
Understanding allotted systems is equally important due to the fact modern-day records systems often function across a couple of servers and platforms.
Data Engineering Architecture and Infrastructure
The architecture of a statistics engineering gadget determines how statistics flows through an employer. A normal architecture includes several components which include records resources, ingestion structures, processing engines, and storage layers. Data sources might also consist of net programs, cell apps, enterprise structures and external APIs. These assets generate uncooked information that needs to be accumulated and processed.
Data ingestion systems are chargeable for taking pictures and moving facts from resources into processing structures. This procedure can occur in actual time or in batches relying on the enterprise requirement. Processing engines transform raw facts into established codecs that can be analyzed. These systems smooth, clear out, and enhance data to make sure it’s far correct and beneficial.
Finally, garage structures maintain processed records in a centralized place where it may be accessed with the aid of analytics gear and dashboards.
Tools Used via Data Engineering Teams
Data engineering groups depend upon a huge range of tools to build and preserve records infrastructure. Some tools are designed for information ingestion and pipeline control. These tools automate the movement of data among systems and assist keep workflow reliability.
Other gear attention on big-scale information processing. These structures permit engineers to process huge datasets quickly and effectively. Data storage structures are every other crucial a part of the technology stack. They offer scalable environments for storing dependent and unstructured data.
Workflow orchestration tools help engineers agenda and monitor information pipelines. These systems ensure that information tasks run at an appropriate time and complete correctly.
Building a Scalable Data Pipeline
A scalable statistic pipeline is vital for handling increasing volumes of record . Data engineering teams design pipelines that may method massive datasets without slowing down gadget overall performance. The first step in building a pipeline is figuring out records sources. Engineers decide where the records originates and how often it needs to be amassed.
Next, information ingestion structures seize information from these resources and move it into processing environments. Engineers may additionally use batch processing or actual-time streaming depending on the use case. Data transformation is some other critical step. Raw statistics is frequently incomplete or inconsistent, so engineers clean and standardize the facts before storing it.
Finally, the processed facts is loaded into storage platforms in which analysts and statistics scientists can access it for reporting and modeling.
Data Quality and Governance
Data exceptional is a prime problem for companies that rely closely on analytics. Poor-exceptional information can result in erroneous insights and bad enterprise decisions.
Data engineering groups implement validation guidelines and monitoring systems to make sure that facts is correct and dependable. These structures discover errors, missing values, and inconsistencies all through processing. Data governance regulations also play a key role in managing statistics get entry to and protection. Engineers paintings with compliance teams to ensure that information handling practices meet regulatory requirements.
Proper governance ensures that sensitive information is covered and only handy to legal customers.
Collaboration Between Data Engineer and Data Scientist
Data engineers and statistics scientists paintings carefully together in data-pushed organizations. While statistics engineers recognition on constructing infrastructure, information scientists attention on reading statistics and developing predictive fashions. Data engineering groups offer easy and based datasets that data scientists can use for analysis. Without dependable information pipelines, statistics scientists might spend most in their time getting ready information rather than building fashions.
Effective collaboration between these teams enables companies accelerate innovation and improve analytical results.

Challenges Faced by using Data Engineering Teams
Despite their importance, statistics engineering groups frequently face numerous challenges. One commonplace task is coping with large volumes of statistics from a couple of assets. Integrating information from exceptional systems may be complicated and time-consuming. Another mission is maintaining statistics best. As information pipelines grow in complexity, ensuring accuracy will become extra difficult.
Scaling infrastructure is also a prime challenge. Systems have to be able to manage developing workloads with out growing operational fees extensively.
- Managing large and complex data volumes
- Ensuring data quality and accuracy
- Integrating data from multiple sources
- Maintaining data security and compliance
- Scaling data infrastructure efficiently
- Handling real-time data processing
- Managing high infrastructure and tool costs
- Keeping up with rapidly evolving technologies
Security and compliance necessities also can add complexity to statistics engineering approaches.
Best Practices for Managing Data Engineering Teams
Organizations can improve the overall performance of data engineering teams by following several quality practices. Clear documentation is vital for dealing with complex records structures. Engineers must document pipelines, workflows, and machine architecture. Automation ought to also be prioritized. Automated pipelines reduce manual paintings and decrease the chance of errors.
Monitoring and logging structures help groups discover problems quick and maintain pipeline reliability.
Organizations have to also spend money on schooling packages that maintain engineers updated with new technologies and first-class practices.
Future Trends in Data Engineering
The field of records engineering continues to conform unexpectedly as new technology emerge. Cloud-native facts systems are getting increasingly famous due to the fact they provide scalability and versatility. Real-time facts processing is likewise gaining importance as corporations are searching for to make quicker decisions based totally on live facts streams. Artificial intelligence and system learning are anticipated to play a more function in automating information pipeline management and optimization.
- Growth of real-time data processing
- Increased adoption of cloud-based data platforms
- Integration of AI and machine learning in data pipelines
- Rise of data automation and smart workflows
- Expansion of data governance and security frameworks
- Growth of data lakehouse architectures
- Increased use of edge computing for data processing
As statistics volumes continue to grow, the call for for skilled facts engineering teams will stay robust.
Conclusion
Building Data Engineering Teams for Success requires extra than just hiring skilled engineers. It includes growing a strong basis of collaboration, clear goals, contemporary gear, and scalable statistics architecture. When organizations invest inside the proper information infrastructure and empower their groups with green workflows, they liberate the genuine cost of information.
Successful information engineering teams recognition on facts first-class, automation, security, and continuous development. By implementing first-rate practices along with sturdy records governance, cloud-primarily based pipelines, and powerful conversation between groups, companies can transform uncooked facts into significant insights that drive smarter decisions.




